
Digitalizace minulosti s nástroji budoucnosti
Pro časopis Bulletin SKIP jsme připravili článek pod názvem „Digitalizace minulosti s nástroji budoucnosti.“ Digitalizace není pouze tvorba digitální podoby dokumentu. Díky technologii vytěžování dat je možné v dokumentech vyhledávat a orientovat se v logické struktuře dokumentu.
Prohlédnou si celý článek
Technologie OCR („optical character recognition“) je nástroj na vytěžování dat z dokumentu, který je postaven na rozpoznávání tištěného textu. U ručně psaného textu je rozpoznání o něco složitější a může tudíž docházet k vyšší chybovosti.
V tomto ohledu pracujeme na vývoji unikátního nástroje na rozpoznání ručně psaného písma, který kromě funkce rozpoznání písma přinese širší možnosti vyhledávání. Více o aplikaci InkCapture.
Na obrázku je pro ukázku znázorněna identifikace textu a extrakce informací z rukopisu z roku 1917.
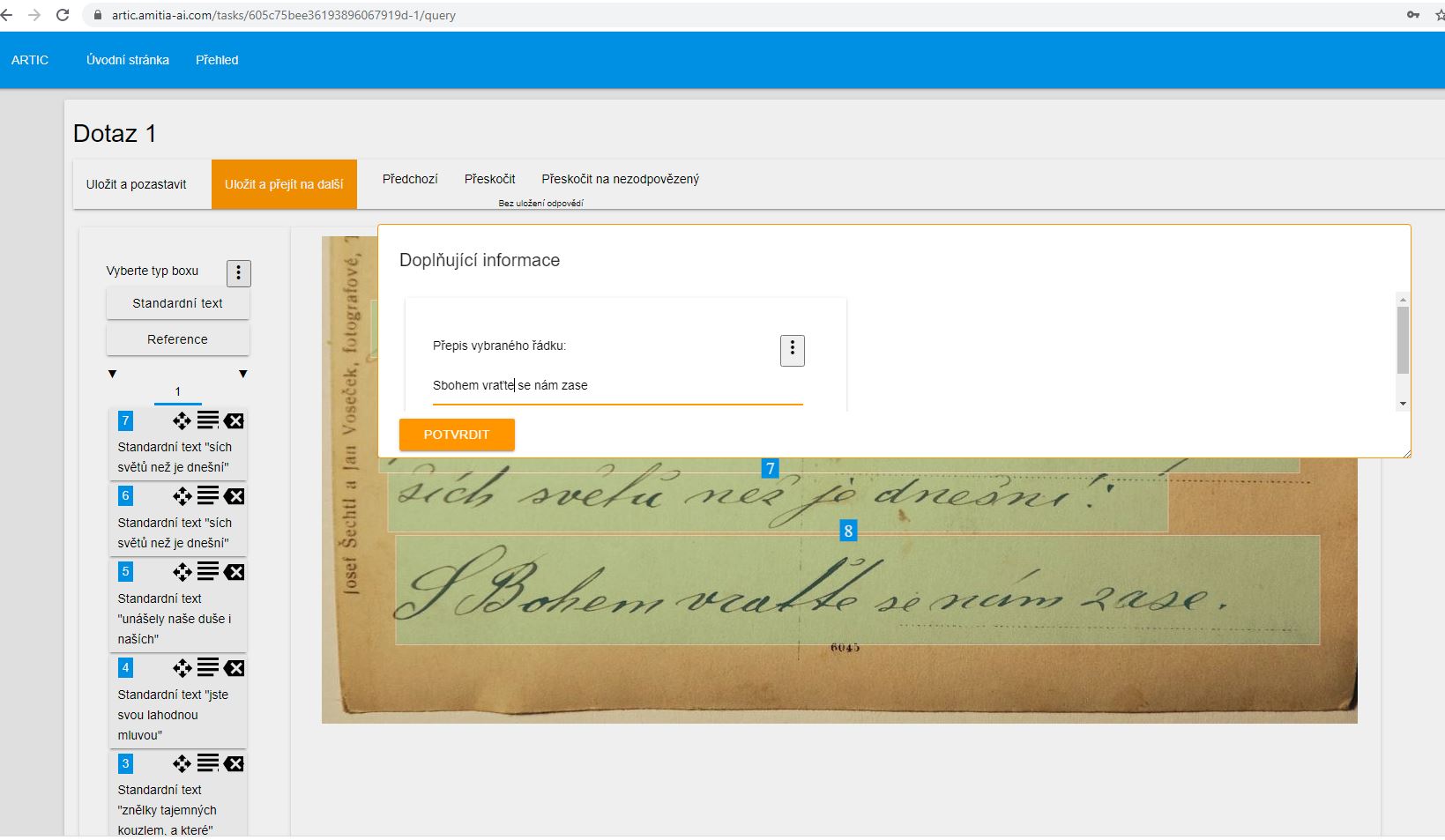
Anotace dat z ručně psaného písma (zdroj: Autor: Jan Sommer. Dostupné z: Flickr.com, získáno 25.3.2021)
Na následujícím obrázku je znázorněna identifikace textu a extrakce informací z textu na dopravním značení.
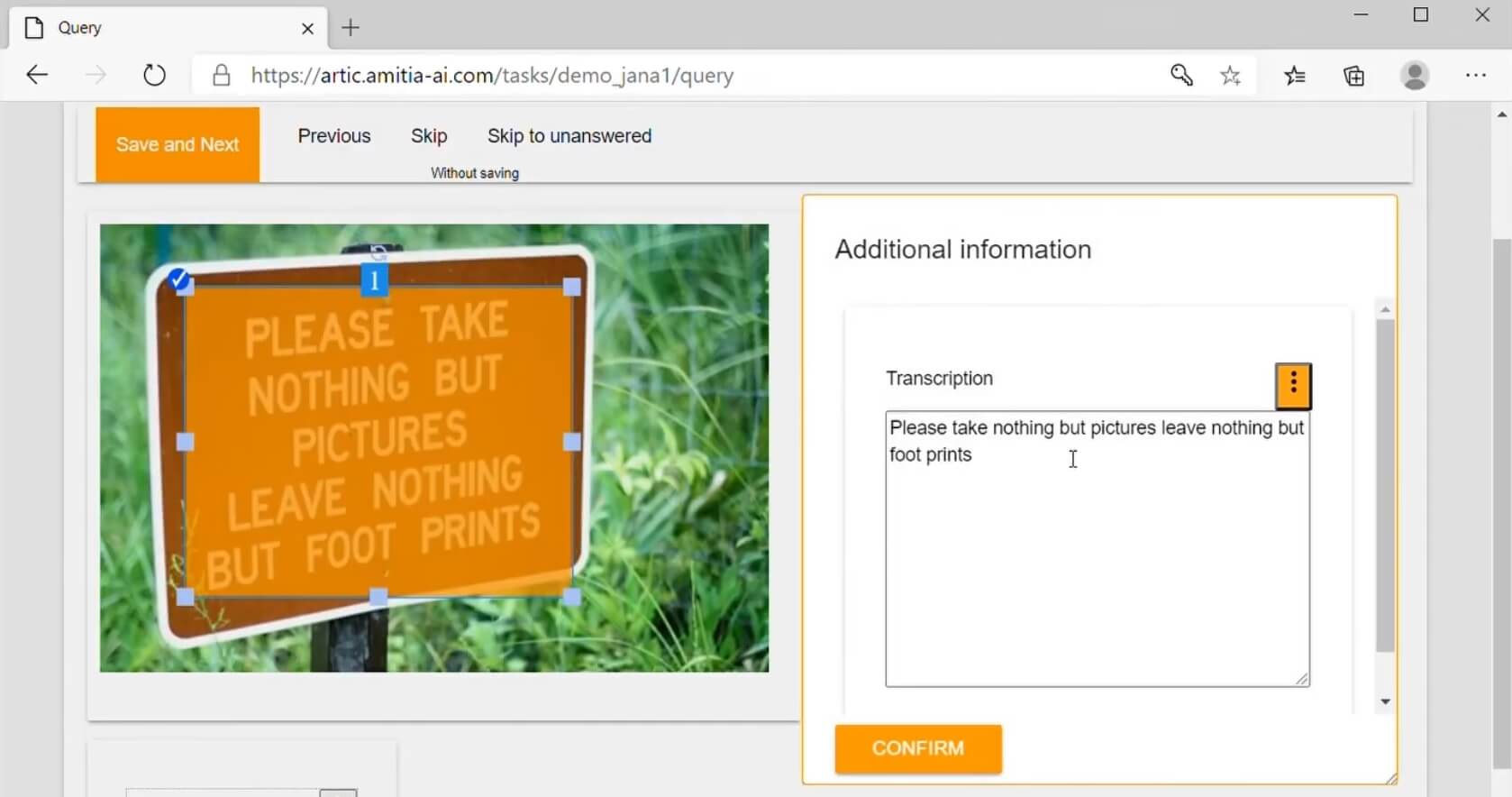
Příklad anotace dat z textu dopravního značení (zdroj: MarkIt | Amitia AI. Amitia AI | Your partner for AI solution, dostupné z: Amitia-ai.com, získáno 25.3.2021)
Druhým v článku zmíněným nástrojem pro digitalizaci kulturního obsahu je KAITOS, který umožňuje správně určit logickou strukturu dokumentu, zpracovat digitalizované předlohy a připravit data pro generování PSP balíčků metadat pro digitální knihovnu.

Příklad detekce textu z novinových článků (zdroj: Rudé právo 17.11.1920, oddělení časopisů Knihovny Národního muzea, sign. Z 18 A 1, dostupné online z digitální knihovny Kramerius, získáno 24.3.2021)
Na obrázku je znázorněn postup strojového učení. Předlohy je možné roztřídit do různých tříd, přesně identifikovat jednotlivé bloky a indexovat pro budoucí vyhledávání.
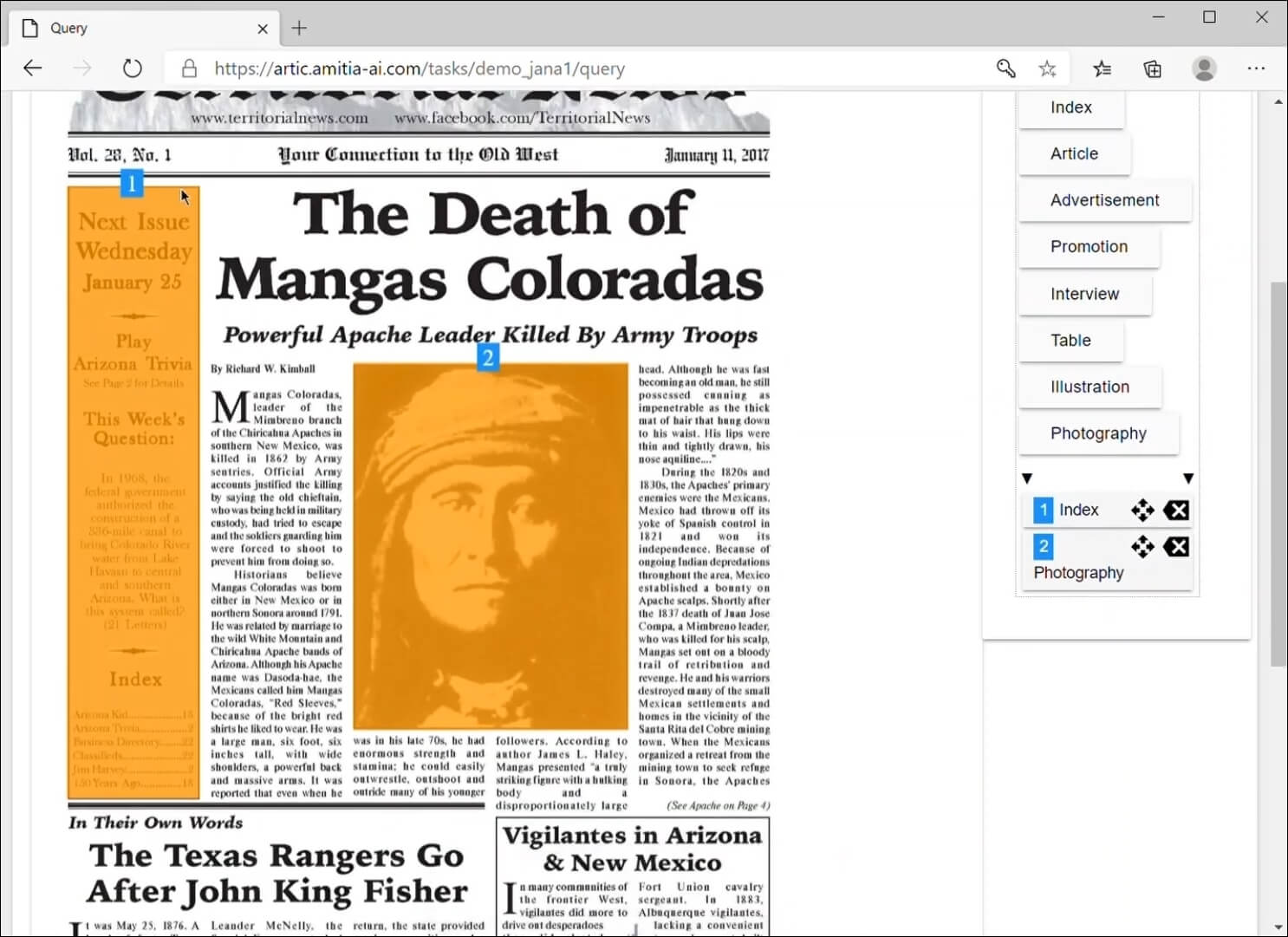
Postup anotace dat I (zdroj: MarkIt | Amitia. Dostupné z: Youtube. Kanál Zaměstnance Amitia, získáno 25.3.2021)
Další postup je znázorněn na následujícím obrázku. V odkazovaném videu je možné si celý proces prohlédnout.
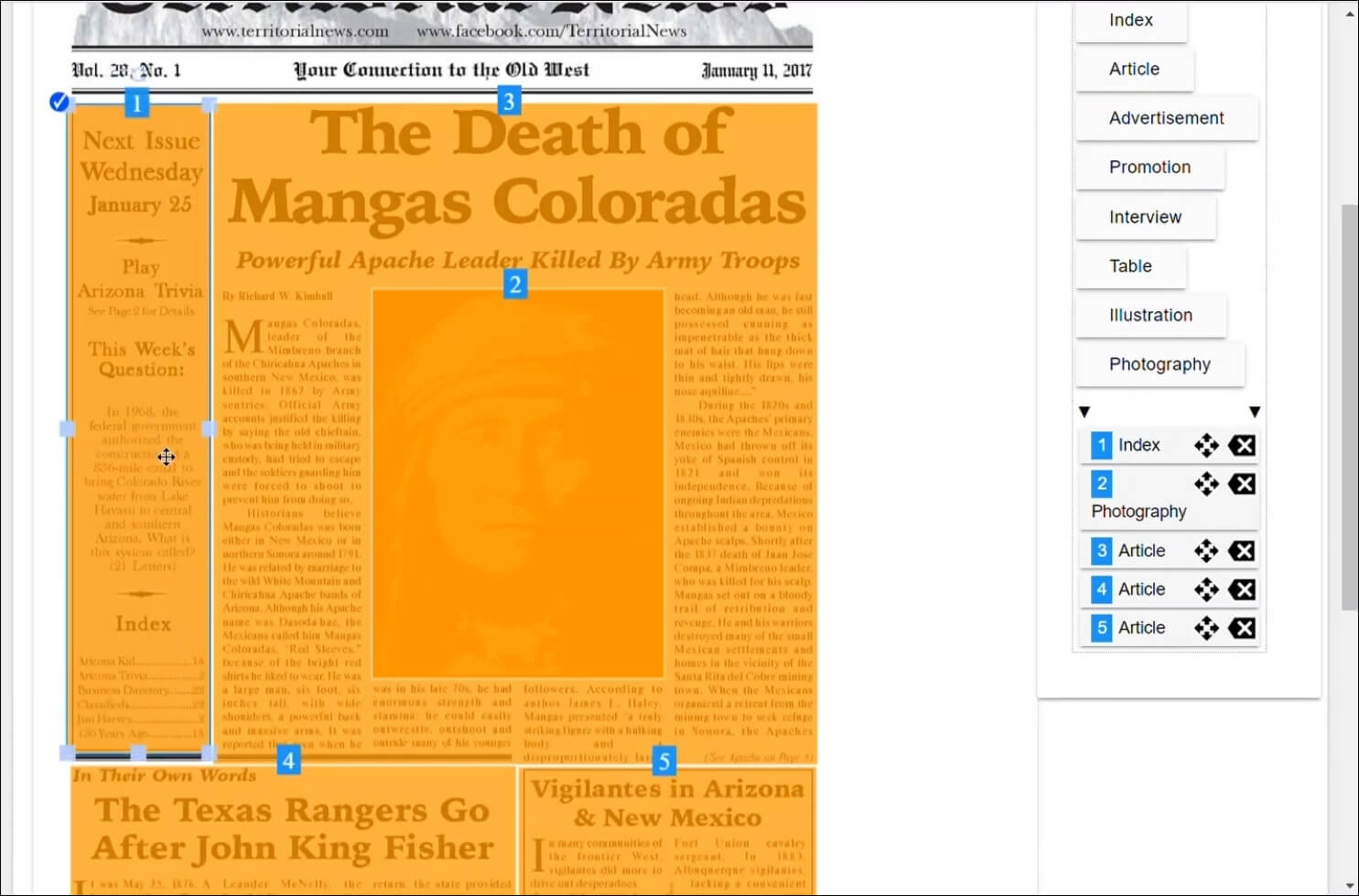
Postup anotace dat II (zdroj: MarkIt | Amitia. Dostupné z: Youtube. Kanál Zaměstnance Amitia, získáno 25.3.2021)
Mohlo by se vás také zajímat

Jaký je rozdíl mezi OCR a ICR?.
OCR (optical character) a ICR (intelligent character) systémy se využívají na vytěžování dat, což je klíčová část digitalizace.

7 důvodů, proč si nechat digitalizovat dokumenty
Digitalizace formou služb přináší nespočet výhod pro koncového zákazníka. Ptáte se, jaké to mohou být?
Více článků od společnosti EXON